






在撰写本文时,Bun 拥有超过 2,600 个未解决的 GitHub 问题。我们很乐意收到用户和反馈,但有些问题对我们来说很难重现和调试。
应用程序和 SaaS 产品可以使用 Sentry 等出色的崩溃报告服务,但对于 Bun 这样的 CLI 工具,上传核心转储存在隐私、性能和可执行文件大小方面的权衡,这些权衡更难证明其合理性。
因此,在 Bun v1.1.5 中,我为 Zig 和 C++ 崩溃报告编写了一种紧凑的新格式。崩溃报告适合放入一个大约 150 字节的 URL 中,其中不包含任何个人信息。
为什么不直接使用操作系统崩溃报告器?
macOS 等一些操作系统具有内置的崩溃报告器,但这通常意味着需要随应用程序一起打包调试符号。对于 Linux,这些调试符号大约为 30 MB,而 macOS 大约为 9 MB。
du -h ./bun60M ./bunllvm-strip bundu -h ./bun51M ./bun而在 Windows 上,.pdb 文件超过 250 MB
(gi bun.pdb).Length / 1mb252.4492187530 MB - 250 MB 是添加到 Bun 的每次安装中的巨大体积。
但是,没有调试符号,崩溃的报告非常有限。而且,有了 地址空间布局随机化,所有的函数地址都变得无用了。
uh-oh: reached unreachable code
bun will crash now 😭😭😭
----- bun meta -----
Bun v1.1.0 (5903a614) Windows x64
AutoCommand:
Builtins: "bun:main"
Elapsed: 27ms | User: 0ms | Sys: 0ms
RSS: 91.69MB | Peak: 91.69MB | Commit: 0.14GB | Faults: 22579
----- bun meta -----
Search GitHub issues https://bun.net.cn/issues or join in #windows channel in https://bun.net.cn/discord
thread 104348 panic: reached unreachable code
???:?:?: 0x7ff62a629f17 in ??? (bun.exe)
???:?:?: 0x7ff62a907a83 in ??? (bun.exe)
???:?:?: 0x7ff62a61f392 in ??? (bun.exe)
???:?:?: 0x7ff62ade7ff1 in ??? (bun.exe)
???:?:?: 0x7ff62ab2193c in ??? (bun.exe)
???:?:?: 0x7ff62ab21166 in ??? (bun.exe)
???:?:?: 0x7ff62cd3ddeb in ??? (bun.exe)
???:?:?: 0x7ff62b7a4bb6 in ??? (bun.exe)
???:?:?: 0x7ff62b7a33bd in ??? (bun.exe)
???:?:?: 0x1bab9ca115d in ??? (???)
???:?:?: 0x1bab9ca111f in ??? (???)
新的崩溃报告器
在 Bun v1.1.5 中,当发生崩溃或恐慌时,Bun 会打印类似这样的消息:
Bun v1.1.5 (0989f1a) Windows x64
Args: "C:\Users\chloe\.bun\bin\bun.exe", ".\crash.js"
Builtins: "bun:main"
Elapsed: 40ms | User: 15ms | Sys: 15ms
RSS: 92.80MB | Peak: 92.80MB | Commit: 0.14GB | Faults: 22857
panic(main thread): Internal assertion failure
oh no: Bun has crashed. This indicates a bug in Bun, not your code.
To send a redacted crash report to Bun's team,
please file a GitHub issue using the link below:
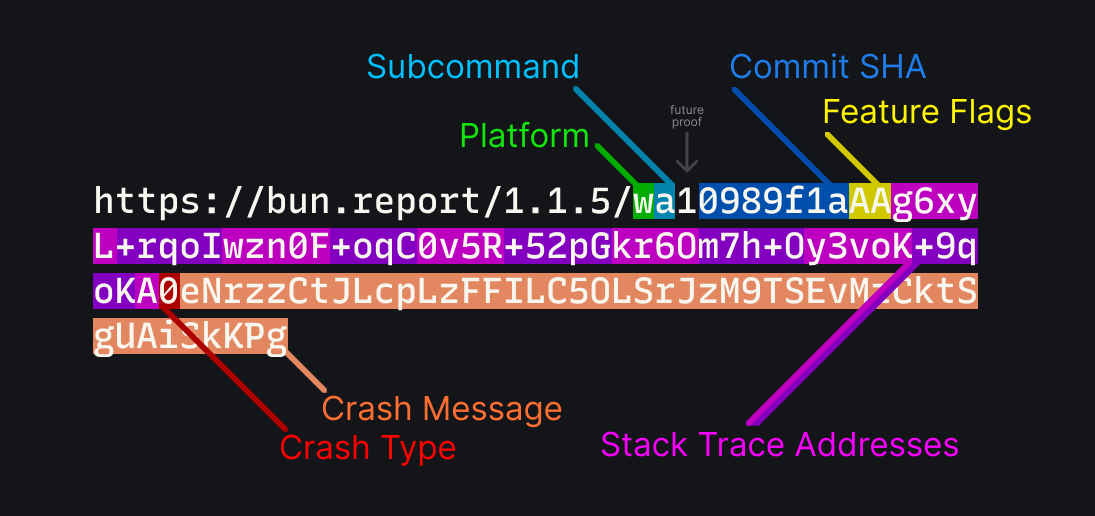
https://bun.report/1.1.5/wa10989f1aAAg6xyL+rqoIwzn0F+oqC0v5R+52pGkr6Om7h+Oy3voK+9qoKA0eNrzzCtJLcpLzFFILC5OLSrJzM9TSEvMzCktSgUAiSkKPg
这个 bun.report 链接,当被点击时,会重定向到打开一个预先填充的 GitHub 问题表单,其中重新映射的堆栈跟踪被编码在 URL 中。
让地址有用
函数地址是指向应用程序代码加载位置的内存指针,其中包括出于安全原因而随机化的偏移量。这意味着如果我们尝试对其进行解码,将一无所获。
llvm-symbolizer --exe ./bun.pdb 0x7ff62a629f17 0x7ff62a907a83??
??:0:0诀窍是简单地将地址减去二进制文件的基地址。
pub fn getRelativeAddress(address: usize) ?usize {
const module = getModuleFromAddress(address) orelse {
// Could not resolve address! This can be hit for some
// Windows internals, as well as JIT'd JavaScript.
return null;
};
return address - module.base_address;
}
实际上,这个函数 复杂得多,因为每个平台都有不同的 API。
注意 - 我上面所说的“模块”仅适用于 Windows。在 macOS 上它被称为“映像”,在 Linux 上被称为“共享对象”。它们都指代内存中已加载的库或可执行文件的相同概念。为简单起见,我将继续称它们为“模块”。
- Windows:调用
GetModuleHandleExW并带上GET_MODULE_HANDLE_EX_FLAG_FROM_ADDRESS标志。基地址是模块的指针。 - Linux:使用
dl_iterate_phdr迭代已加载的模块,一旦找到一个原始地址包含在其中的模块,dl_phdr_info结构体中的.dlpi_addr就是基地址。 - macOS:可以使用函数
_dyld_image_count和_dyld_get_image_header来迭代模块,然后_dyld_get_image_vmaddr_slide获取 ASLR 的滑动量。- 生成的地址仍然包含到映像的偏移量(对于 Bun,它是
0x100000000,可以使用image list在 lldb 中列出)。为了编码更短的 URL,此偏移量被移除,但 在重新映射之前必须重新添加,否则llvm-symbolizer会失败。
- 生成的地址仍然包含到映像的偏移量(对于 Bun,它是
对于 Linux 和 macOS,第一个模块是指主应用程序二进制文件。在 Windows 上,您可以将模块名称与 peb.ProcessParameters.ImagePathName 进行比较,以确定它是否为主二进制文件。
通常,一旦解析了模块和相对地址,应用程序就会立即打开调试符号并进行函数名称解码。为了避免下载和解析调试符号的成本,我们将解码工作交给服务器。该服务器可以缓存所有调试符号,并在几秒钟内解码堆栈跟踪。同时,它可以作为打开新 GitHub 问题的链接。
bun.report 的 URL 结构
让我们再看看这个 URL,并分解它是如何编码的。
- 平台:一个表示平台的单个字符。
w代表 x86_64 Windows,M代表 aarch64 macOS,以此类推。 - 子命令:一个表示 子命令 的单个字符,例如
bun test、bun install或bun run。 - 提交 SHA:当前 Bun 版本的提交 SHA。这用于稍后获取调试符号。
- 功能标志:指示在 Bun 崩溃前使用了哪些 API 和功能。
- 堆栈跟踪地址:前面计算出的地址。
- 崩溃类型:一个表示 崩溃类型 的单个字符。
- 崩溃消息:崩溃的消息,其格式取决于类型。
注意 - URL 中的版本号实际上只是一个展示。这样,给定上述信息,就可以手动了解很多关于崩溃的信息。例如,您可以通过平台标识符 w 快速识别 Windows 崩溃。不太明显的是,您可以通过查看字符串末尾附近的 A2 来识别段错误。
VLQ 很有趣
为了使 URL 保持合理的长度,堆栈跟踪地址使用 base64 变长量(Variable Length Quantity)编码。这允许使用更少的字符来编码较小的数字,同时仍然能够编码较大的数字。这是 JavaScript 源映射中用于存储行号的相同技术。
转换过程如下。请注意 VLQ 如何将较小的地址编码为较小的数字。

服务器可以 将它们解码回相对地址,使用提交哈希和平台 下载调试符号,并使用 llvm-symbolizer 来解码函数名称。
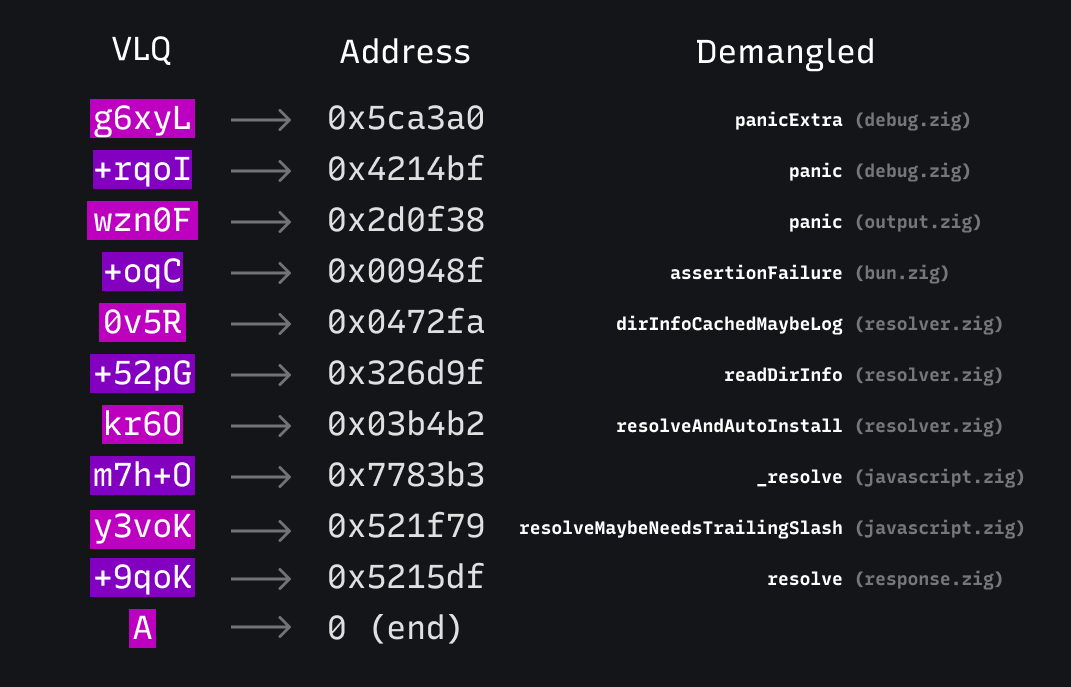
现在显而易见发生了什么:在 dirInfoCachedMaybeLog 中触发了一个断言,该断言来自 Windows 上的模块解析器代码的一部分。
什么是“功能”
URL 还编码了一个 64 位整数,其中每一位对应 Bun 中某个功能是否被使用。这些标志提示了哪些 API 和系统可能导致了崩溃。例如,当自动加载任何 .env 文件时,就会设置 dotenv 功能;当使用 fetch() 时,就会设置 fetch 功能,以此类推。(完整列表)
Zig 的编译时元编程使得创建这个位域变得容易。我们已经有一个用于跟踪功能的全局变量容器。
pub const Features = struct {
pub var bunfig: usize = 0;
pub var http_server: usize = 0;
pub var shell: usize = 0;
pub var spawn: usize = 0;
pub var macros: usize = 0;
// ... and so on
};
而在各种 API 中,我们会递增这些数字来标记功能的用法。
要将这些编码为单个 u64 整数,我们可以使用 std.meta 来遍历功能列表并创建一个列表。
pub const feature_list = brk: {
const decls = std.meta.declarations(Features);
var names: [decls.len][:0]const u8 = undefined;
var i = 0;
for (decls) |decl| {
if (@TypeOf(@field(Features, decl.name)) == usize) {
names[i] = decl.name;
i += 1;
}
}
const names_const = names[0..i].*;
break :brk names_const;
};
然后,可以动态派生一个打包结构,为每个功能使用一位。这个结构就像一个整数,但交互方式像一个结构体。
// note: some fields omitted for brevity
pub const PackedFeatures = @Type(.{
.Struct = .{
.layout = .@"packed",
.backing_integer = u64,
.fields = brk: {
var fields: [64]StructField = undefined;
for (feature_list, 0..) |name, i| {
fields[i] = .{ .name = name, .type = bool };
}
fields[feature_list.len] = .{
.name = "__padding",
.type = @Type(.{ .Int = .{ .bits = 64 - feature_list.len } }),
};
break :brk fields[0..feature_list.len + 1];
},
},
});
最后,当 Bun 崩溃时,可以使用 inline for 来非常简单地构建位域,这是一种在编译时迭代某物,但在运行时执行内部内容的方法。
pub fn packedFeatures() PackedFeatures {
var bits = PackedFeatures{};
inline for (feature_list) |name| {
if (@field(Features, name) > 0) {
@field(bits, name) = true;
}
}
return bits;
}
现在,将新功能添加到原始结构 Features 中将在崩溃报告器中得到正确处理,而无需重复劳动。
使用 C 或 Rust 通过宏来实现这一点是可能的,但我认为使用 Zig 的 comptime 会更简单、更易读。
与核心转储相比如何?
核心转储包含更多信息,但它们非常庞大,需要调试符号才能有用,并且包含许多潜在敏感或机密信息。
我们希望避免在报告中发送任何 JavaScript/TypeScript 源代码、环境变量或其他敏感信息。这就是为什么我们只发送 Zig/C++ 堆栈跟踪和其他一些详细信息的原因。与其默认发送所有内容,不如采用这种方法,只发送我们(可能)需要诊断问题的部分。如果我们发现需要更多信息,我们可以要求用户提供,但这比我们之前拥有的、一堆未映射地址的“一无所有”要好得多。
演示
为了将所有内容整合在一起,我编写了一个小型 Web 应用,让您可以测试崩溃报告器,该应用可在主页 bun.report 上找到。如果您将 /view 追加到任何崩溃报告 URL 的末尾,您也会来到这里。
Bun 正在旧金山招聘
如果您有兴趣从事此类项目,我们正在旧金山招聘工程师!我们正在寻找系统工程师来帮助构建 JavaScript 的未来。在此申请